Best practice – by definition – constantly evolves, and so do training methods.
 Lately we have had some feedback to
the effect that the ready-built scenario model
for our WiMAX-DSL training course was too much too soon, and that it would be easier
to start with something simpler, in order to gain the basic principles before rushing
on to something (the current model) which showcases STEM’s power more comprehensively.
Lately we have had some feedback to
the effect that the ready-built scenario model
for our WiMAX-DSL training course was too much too soon, and that it would be easier
to start with something simpler, in order to gain the basic principles before rushing
on to something (the current model) which showcases STEM’s power more comprehensively.
Therefore, a number of ‘blank sheet’ exercises, designed to foster an
early intuition for the STEM paradigm, have been improvised in recent training assignments,
and are now being drafted into our regular training guide. To avoid any preconceptions
and distractions, these exercises are based intentionally on topics outside of telecoms,
albeit communications in the transport sense.
School buses: the simple case
Imagine a school with n pupils, x% of which live far enough away to
require transport by a school bus with a maximum capacity of 50 seats (not including
the driver). How many buses do you need, and if the school population is growing,
when might you need to buy an extra bus?
This is the archetypal STEM problem which could be represented as simply one service
element (how many children need rides?) and one resource element (how many children
per bus?). However, we will choose to structure this more conventionally with a
market segment element for the school population in case we decide to model the
provision of school lunches to a different subset later. (We will assume that reasonable
routes to school can be found to fill the buses as efficiently as possible. The
harder problem of multiple buses driving simultaneously to multiple schools is examined
later).
Taking n as 300 and x as 30, then you would create a STEM model like
this, and it would immediately calculate that 2 buses are required:
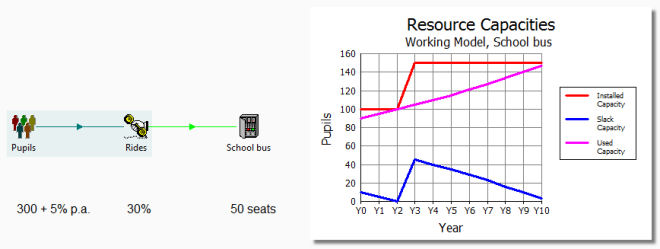
Simple school bus model
If the population was growing at 5% p.a., then STEM would ‘install’
the next bus after 3 years. If each bus has an operational lifetime of ten years,
costs EUR60,000 to buy, EUR4800 p.a. to maintain and EUR5000 p.a. to operate, then
STEM would also tell you the cost of subsidising the service. (You might want to
model the driver too.)
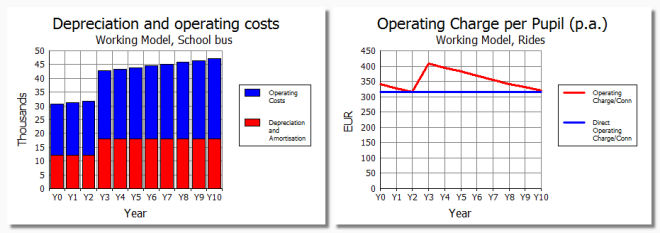
Cost of owning and operating the bus fleet, and then how this is allocated per pupil
Multiple schools, all with the same start time
Consider a local education authority with responsibility for 10 schools, with a
total population of 3000 (and the same 30% requiring a bus to school). Simply bumping
up the numbers won’t do, as you would conclude that 18 (= 900/50) fully-occupied
buses would suffice; whereas any one school in the original example would actually
have had ten seats spare across two buses. We would prefer not to run the model
ten times to get (close to) the right result. Cue the location element, a concise
way to express the fact that demand is distributed in more than one place. As a
general rule, geography has two impacts:
- it ensures that every school with children has at least one bus (consider what you
might calculate if the total population was only 300 across 10 schools, back to
requiring a total of 90 seats); and
- it ensures that a suitable allowance is made for those unoccupied seats at each
separate school.
Remember also that there will be a natural variance in bus-ride numbers (or in spare
seats, depending on how you look at it), making it unlikely that you would achieve
90% occupancy on every school bus.
In the STEM model, plug in a location element, with sites set to 10 schools, and
linked to the resource with distribution set to Monte Carlo1, and then
look at the results.
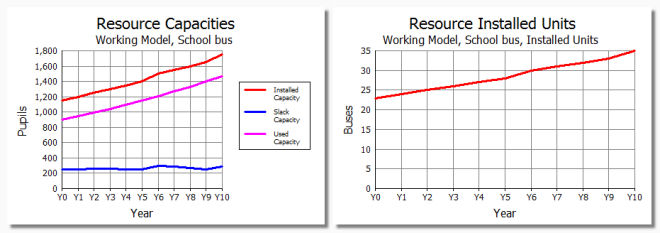
Simulated geographical overhead of spare bus seats and corresponding number of buses
Not only do we get back to (at least) two buses (ten spare seats) per school, but
in fact we find we need 23 buses at the start. Some of the schools have sufficiently
more than 90 pupils to require another bus (and more will exceed 100 pupils than
might fall below 50). Then plug in the 5% p.a. growth and watch the results.
The next logical step in this progression is to use template replication to model
the actual school numbers, one by one, and we will do this live at the User Group
in October. For now, we turn our attention from per-customer dimensioning (implicit
in the common school arrival time) to traffic loading in terms of actual concurrent
usage. For this aspect we imagine a fleet of taxis.
Running enough taxis at rush hour
Imagine a town with a population of 10,000 and, for the sake of argument, all town
dwellers using the taxi service for an average of 30 minutes per week, with no particular
bias between weekdays and the weekend. If 20% of the daily taxi demand fell in the
morning rush hour, then how many taxis would you need to provide a good service?
Again, this is a classic STEM service description, where you could have a market
segment element of 10,000 people and a service with 30 × 365/7 ‘Taxi
Minutes’ per person to calculate the ‘rush-hour traffic’ in ‘Taxi
Erlangs’. In plain English, this would mean how many simultaneous taxi journeys
on average during the busiest hour? (For simplicity, assume all taxis are occupied
by a single person.)
Naturally one would expect some variance amid the usage during that busy hour, and
therefore STEM is pre-programmed with an Erlang B function to calculate how many
taxis you would need (average plus some overhead) to achieve a better than x%
probability of all taxis being taken when you need one (‘blocking’).
Create a transformation, change the type to Erlang B, and choose a Grade of Service
(GoS) of 1% (0.01).
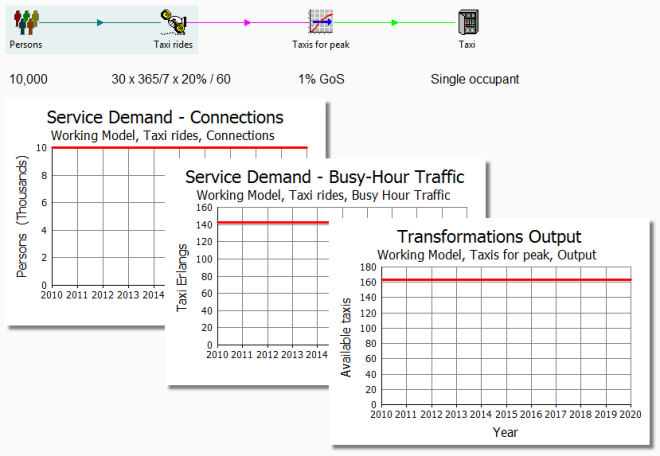
Estimating rush-hour demand for taxis in a single town
You could expand this to cover say 15 similar but quite separate towns by bumping
up the numbers. With an effective capacity of 1 passenger you would not need to
worry about spare seats. However, it would still be the case that a taxi in town
A would not be available to give a ride in town B. So the averaging effect to achieve
the 1% GoS should consider only a population of 10,000 per town, not 150,000 all
together balancing some of the peaks. Fortunately the Erlang B transformation allows
you to specify a number of sites (inferred from a location element) to capture this
disaggregated overhead effect.
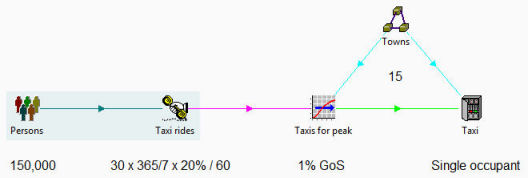
Taxi overhead calculation localised to separate towns
As a further exercise, you might like to turn this into a template in order to model
several categories, say of big, medium and tiny towns.
These simple exercises are an effective way to gain a quick grasp of fundamental
STEM calculations and illustrate the generality of the methodology which may be
applied to many other sectors outside telecommunications.
1 If you don’t know what the Monte Carlo distribution is (not the
same as a Monte Carlo walk), then you would probably benefit from one of our training
courses, or at least to join the audience participation at the User Group.