STEM 6.2
 STEM version 6.2 was released on 30 April 2003, featuring time-series views in the
Editor, persistent formatting of graphs and tables in the Results Program, and a
powerful new template-replication feature with the potential to massively streamline
the service and cost structures of large models.
STEM version 6.2 was released on 30 April 2003, featuring time-series views in the
Editor, persistent formatting of graphs and tables in the Results Program, and a
powerful new template-replication feature with the potential to massively streamline
the service and cost structures of large models.
Examining assumptions with time-series views
STEM has always used parameterised time-series inputs, such as Exponential Growth
or Interpolated Series, as a way to enable rapid model development from concise
and manageable assumptions. However, this approach lacks the immediacy of the more
familiar spreadsheet interface, and the ability to scroll across and review the
actual numbers for each year, and especially the value in the last year (or period)
of the model run.
Time-series views are an optional extension to the standard data-dialog interface
which present the numeric values calculated from the underlying parameters in a
spreadsheet-like tabular display. Key parameters are highlighted and can be edited
directly (just as in the conventional dialogs for these parameters). Calculated
values appear in grey, and can also be modified directly. In the example below,
the 50% Base of an Exponential Growth is displayed in black in the column for Y0
(which is the Base Period for the series), while the remaining values are shown
in grey.
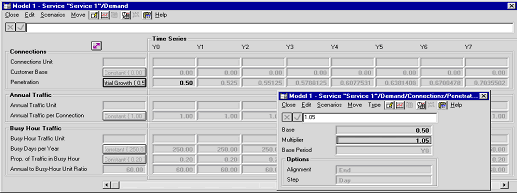
Time-series view for Service Demand
Managing complexity with template replication
The natural evolution of many business models, whether in STEM or any other platform,
tends to involve the manual replication of core fragments of model structure, perhaps
for different customer segmentations or service types, or for different geographical
classifications, by cost or by configuration.
Manual replication is time-consuming and tedious: copied elements must be renamed
and tailored to suit the needs of each individual copy. Moreover, there is no direct
way to verify the consistency of the copied elements as part of an auditing process.
This second point becomes critical when, almost inevitably, some change is required
within the original core fragment. The only alternative to making the same changes
in parallel is to revert to the original model and repeat the copying – but both
processes are tedious and susceptible to human error, especially after several iterations.
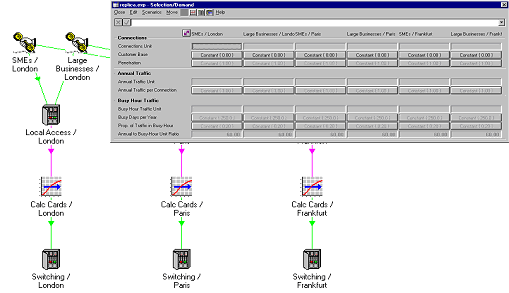
Manually copied model structure
Such a manual approach to a complex model is counter-intuitive. If you were to describe
the structure of such a model to a colleague, you would not describe the original
fragment, and then repeat all the detail for each copy. Rather, you would describe
the original, and then explain that the structure is replicated for several named
variants, specifying in detail only how the respective variants differ.
STEM’s template replication concept allows you to translate this principle
of concision into software. Firstly, elements which must be reproduced for multiple
geographical areas are identified as a template, together with the key differentiating
parameters. Secondly, the names of separate geographical areas are specified, together
with the corresponding key values for each area. STEM then automatically generates
an expanded model with template replication for the named areas, and implicit aggregation
for common model features, e.g. backbone network traffic, in a process that is logical,
concise, extensible and easy to maintain and audit.
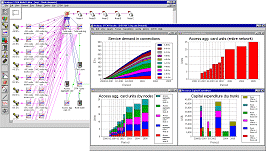
Achieving continuity with results workspaces and views
The Results program can save a workspace which enables the working environment to
be persistent from one session to the next. The workspace file specifies the full
set of loaded models and the results configuration, together with the layout and
formatting of all current graphs and tables, which are then restored at the start
of the next session.
In addition, you can fix a number of separately arranged and formatted graphs and
tables as a series of results Views, stored within the workspace. The ability to
call up this pre-arranged sequence facilitates the process of verifying a certain
set of results as a model is being developed, and is also very convenient for presentational
purposes.
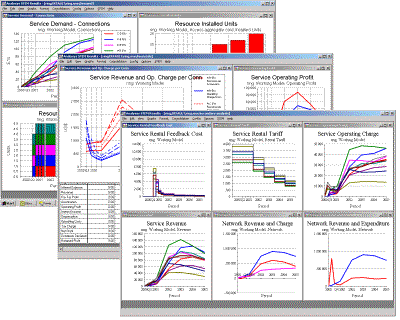
Leaner models without Functions
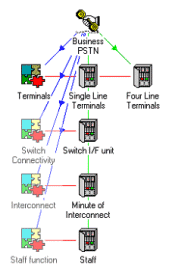 The
original STEM methodology for the supply side of a network was built around the
concept of logical Functions representing the different roles played by different
physical pieces of equipment, with one or more Resources within each Function capturing
the physical parameters and costs relating to a specific item. This is the fundamental
basis for modelling technology migration, through the automatic take-up of capacity
of one Resource as another in the same Function is either replaced or removed.
The
original STEM methodology for the supply side of a network was built around the
concept of logical Functions representing the different roles played by different
physical pieces of equipment, with one or more Resources within each Function capturing
the physical parameters and costs relating to a specific item. This is the fundamental
basis for modelling technology migration, through the automatic take-up of capacity
of one Resource as another in the same Function is either replaced or removed.
However, in many models, technology migration is limited to a few Functions, if
any. The remaining Resources cannot generally be placed in one Function, as this
would imply that capacity is transferable, i.e. that capacity from one Resource
could be replaced with capacity from another. So the original methodology demanded
separate Functions for the remaining Resources in a model, slowing the model-building
process and cluttering Views with ‘dummy’ Functions.
Now this hierarchy is optional, and Resources can be created at will without the
need for a ‘parent’ Function. Instead, suitably compatible Resources can be grouped
together as required when the Function model is required.
The removal of the rigid Function hierarchy enables a more streamlined user interface
for Resource Requirements. The original Resource Requirement dialog for a Function
has been replaced by an interface which caters for an individual Resource as its
standard form, with a separate time-series table for comparing Mapping inputs when
several Resources are grouped together in a Function.
These re-designed dialogs also provide an interface for defining time-series formulae
for Mapping inputs, and for linking all the assumptions defining a Requirement for
a Service/Transformation × Resource pair to another.